在Spark计算平台中,数据倾斜...提出了广播机制避免Shuffle过程数据倾斜的方法,分析了广播变量分发逻辑过程,给出广播变量性能优势分析和该方法的算法实现.通过Broadcast Join实验验证了该方法在性能上有稳定的提升.
”数据倾斜 分区策略 洗牌算法 广播机制“ 的搜索结果


大数据时代的到来,给数据处理和分析带来了全新的挑战。传统的数据库和数据仓库系统,往往难以满足海量数据、复杂查询、低延迟等需求。为了应对这些挑战,Presto 应运而生,成为了大数据分析领域一颗耀眼的新星。Presto ...


随着互联网、移动互联网、物联网等新型信息技术的发展,以及其相关产业的崛起,越来越多的人开始关注到如何从海量的数据中挖掘出有价值的信息,这是大数据时代的一个重要任务。而在实际工作当中,往往并不会像同行...
Spark是大数据分析的利器,在工作中用到spark的地方也比较多,这篇总结是希望能将自己使用spark的一些调优经验分享出来。一、常用参数说明--driver-memory 4g : driver内存大小,一般没有广播变量(broadcast)时,...
你。
源码解析Spark shuffle过程中的Shuffle Writer的选择

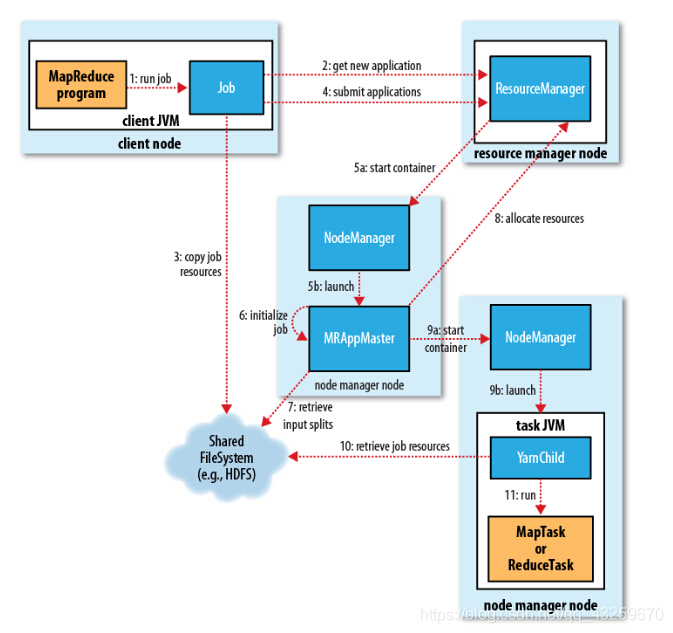
大数据框架的总结复习
下面的所有词汇与例句都是在英国留学期间, 学到的、听到的、见到的,都来自英语母语使用者,其中包括: 学校、同学、教授、教职人员、以及生活中形形色色的人, 这篇文章有助于还没去英国的同学提前掌握一些高频...
1、Spark master使用zookeeper进行HA的,有哪些元数据保存在Zookeeper? 答:spark通过这个参数spark.deploy.zookeeper.dir指定master元数据在zookeeper中保存的位置,包括Worker,Driver和Application以及...
spark 分区 提交 调优
标签: spark
有时候需要重新设置Rdd的分区数量,比如Rdd的分区中,Rdd分区比较多,但是每个Rdd的数据量比较小,则需要重新设置一个比较合理的分区数。或者需要把Rdd的分区数量调大。还有就是通过设置一个Rdd的分区来达到设置生成...
场景1:每个节点复制一张表。每个节点并行连接其本地数据,然后将...这种算法适合于右表很小,而左表很大的情况,因为它可以避免左表的数据传输。但是如果右表也很大,那么这种算法就会占用大量的网络带宽和内存空间。

总结Hive、Spark、Kafka重点

Apache Spark是一个围绕速度、易用性和复杂分析构建...RDD是数据项的集合,这些数据项分为多个分区,并且可以存储在Spark群集中的多个节点上。这样,通过数据分区和并行计算,Spark能够提供快速的数据访问和处理能力。
Flink 作业中,包含两个基本的块:数据流(DataStream)和 转换(Transformation)。DataStream 是逻辑概念,为开发者提供 API 接口,Transformation 是处理行为的抽象,包含了数据的读取、计算、写出。所以 Flink ...
我们介绍了Thrill的设计和性能评估,它是一个通用大数据处理框架的原型,具有方便的数据流式编程接口。Thrill与Apache-Spark和Apache-Flink有些相似,但有两个主要区别。首先,Thrill是基于C++的,它具有直接的本机...
Flink是一个对有界和无界数据流进行有状态计算的分布式处理引擎和框架,既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型,其代码主要由 Java 实现,部分代码由 Scala...


大数据八股文(自用)
标签: 大数据
实现的逻辑是继承GenericUDF,重写evaluate方法,getdisplay方法。打包上传到hdfs路径上或者hive的lib目录 注册自定义的函数UDTF炸裂 一行多输出 TUDAF聚合多行输出一行Aggregate前台是和用户直接交互的界面和各种...
自从2017年12月1日发布spark-2.2.1以来,已有3个月时间。2018年2月28日,spark官方发布了一个大版本Spark-2.3.0,解决了1399个大大小小的问题。一、DataBricks做了相关说明今天,我们很高兴地宣布Databricks上的...

推荐文章
- 『Android 技能篇』优雅的转场动画之 Transition-程序员宅基地
- Webshell绕过技巧分析之-base64编码和压缩编码-程序员宅基地
- 大一计算机思维知识点,大学计算机—基于计算思维知识点详解.docx-程序员宅基地
- 关于敏捷开发的一篇访谈录-程序员宅基地
- 挑战安卓和iOS!刚刚,华为官宣鸿蒙手机版,P40搭载演示曝光!高管现场表态:我们准备好了...-程序员宅基地
- 精选了20个Python实战项目(附源码),拿走就用!-程序员宅基地
- android在线图标生成工具,图标在线生成工具Android Asset Studio的使用-程序员宅基地
- android 无限轮播的广告位_轮播广告位-程序员宅基地
- echart省会流向图(物流运输、地图)_java+echart地图+物流跟踪-程序员宅基地
- Ceph源码解析:读写流程_ceph 发送数据到其他副本的源码-程序员宅基地